In November 2025, we paused new submissions about AI topics. For about three months, we turned away papers about AI models, testing AI models, proposing AI models, theories about the future of AI and so on. We accepted some empirical social science research about AI in society on a case-by-case basis. The purpose of this pause was to ease pressure on our moderators and encourage AI-oriented authors to find other ways of distributing their work — and give us time to craft a policy.
The research and drafting of this policy was done by a subcommittee of our moderation team and steering committee. They were: Alex Hanna, Rebecca Kennison, Sam Koreman, Pamela Oliver, and myself (Philip Cohen). Then we discussed the proposed policy among the full team and committee, and made additional revisions.
We want a policy that will help us protect the epistemic commons from slop that dilutes our work, without spending too much time on each paper. We want to balance the needs and interests of scholars who rely on a more reliable research ecosystem (whether they post papers with us or not), moderators who have to face the queue of papers each day, and the many independent researchers who want to meet scholarly standards with their work but need guidance to do so. We are not trying to monopolize social science research dissemination, and are happy to turn away work that can be more comfortable somewhere else (like aiXiv, which accepts work produced by large language models).
We feel the need to express our humanity in this process. We insist on making human judgments, using our perception, judgment, and experience – and will not defer to automated systems, or enter into a technological arms race to defeat the (people who run the) machines. We strive for fairness, but make no promise of an algorithmically pure policy.
We hope this policy will help us meet our goals, which include disseminating valuable research better and faster, helping scholars understand what types of work that are unacceptable, keeping out fraudulent research and reducing the volume of LLM-generated content, reducing moderation burden, and encouraging honest disclosure of tools and methods.
Because of how quickly things are changing, we expect to revisit this policy periodically. We welcome your feedback, and will do our best to handle appeals.
Someone submitted a paper to SocArXiv that we would have accepted a few years ago.
By our moderation policy, we apply only a very minimal quality standard. In addition to required structural elements — like an abstract, cited references, a title that reflects the content, ORCID, etc. — we sometimes reject papers that don’t surpass “a minimal standard of informative value.” But this paper would have passed it. It was boring, unoriginal, and superficial. Its literature review was deficient. What it claimed as an original theoretical insight was not interesting. It had some complex statistical models, apparently done competently, and graphical as well as tabular results. The citations and in-text quotations appeared to be real. As a whole, it was coherent and relevant to existing research.
At the end of the paper the author included an “AI disclosure.” They listed several AI tools used to generate code, conduct the literature search, “consult” on statistics, and draft the text — they admitted that almost all of the text was generated by these tools. But the author claimed to have formulated the research question, divined the theoretical framework, chosen variables and model specification, “directed analytical decisions,” interpreted the results, and verified every data claim, as well as every citation and quotation. They also shared the statistical code in a public repository, and offered an AI methodology audit on request.
In other words, to reject this paper, we would have to do it based on the nature and extent of the AI tools. As we attempt to formulate a policy for this, I find this case interesting.
I have my own biases. If you told me your only use of AI was to generate your statistical code, I think I would accept your paper (especially if you shared the code). Likewise if you had used AI tools to conduct categorical coding of qualitative data, provided it was human directed and verified. Also, if you told me you only used AI tools to help with writing — fixing style and grammar, language translation, helping to come up with a title or abstract — I think I would accept the paper. And if you told me you used AI to help with your literature search, such as by conducting natural language queries, I think I would accept the paper. But all of these, and writing the first draft, too?
So this paper stands out for using AI tools to do all of this, plus drafting the original text.
One clear position is that using such tools at all is unethical. The models all use people’s work without attribution. I am not persuaded by this, because I think all knowledge is learned from someone else. We have norms for attribution which are partly about ethics, and partly about validity, but there is no standard that says everything you read must be cited. However, these norms are complicated and subject to adaptation, so I don’t rule out changing my mind.
On legality, I think AI training models in principle may be practicing fair use. But it would be a copyright violation if their outputs end up displacing income from the original producers, however — as seems to be the case for news organizations whose content is served to chatbot subscribers. Obviously, I’m not expert on the legal issues, but I’m also not in charge of enforcing copyright law.
Another argument is that platforms like SocArXiv need to defend the scholarly ecosystem from slipping into a self-referencing death spiral of AI slop research generated from AI slop ad infinitum. This might especially be the case for a platform like ours, which accepts work without peer review but assigns DOIs and other trappings of scholarly legitimacy. If you are building a training model to write social science papers, SocArXiv papers would seem to be an attractive (free) target for harvesting.
On the other hand, if we attempt to ban AI-generated research — or even work with limited AI-generated components — we will be entering an endless arms race that we will ultimately lose. In the process, we will spend all our money and time trying to defeat global monopoly powers instead of helping real researchers archive and disseminate their research, which is our mission. And — as I remind people as often as I can — no one should be looking at the corpus of SocArXiv work as a repository of the best research in any field. Most humans come to us with a specific link to a paper, or an author, and get what they need. There is a lot of bad work on our platform — which, unlike most journals and even some preprint servers, we are not shy about admitting — because it doesn’t hurt the good work that is here, and we’re not trying to make money at this. Unless we get so overwhelmed with slop that we can’t maintain the service, I think that if it’s easier to accept bad work than it is to reject it, accepting it might be the more practical course.
Even a requirement like author disclosure of AI tool use could be crippling, because we don’t have the resources to verify claims, or sleuth out people who make false claims or deny using chatbots when they actually do, and so on. ChatGPT et al. read the rules we write, and will happily help authors pretend to comply with them. Again, arms race.
We have been discussing this at SocArXiv, but have not finalized our policy. When we do, I will link it here. In the meantime, we welcome your feedback, ideas, and suggestions — in the comments, or in email to socarxiv@gmail.com, or any other (peaceful) way. (Human-generated, please.) I would especially appreciate discussion that recognizes there are good people with different perspectives and experience, and it would be great if we could find a way to work together.
SocArXiv accepted 3,162 new papers in 2025, an increase of 20% over 2024. We don’t have data on total submissions, but as we noted previously, the volume of new submissions has spiked partly from an influx of AI-generated slop. However, the greater volume of accepted papers (we hope) reflects growth in human research as well. Our new policy of accepting only social science papers, in addition to the moratorium on technical AI research, reinforces this perception.
The rejection rate is much higher than it used to be, which means that our moderation burden has increased substantially. This is exacerbated by the (welcome) fact that new versions of papers now go through our moderation queue. Our team of moderation volunteers deserves our appreciation.
Revised papers are a relatively small share of new uploads. In the 30 days to February 16, we had 500 paper uploads of 454 unique papers. We accepted new versions of 99 papers (some more than once). We accepted 9 papers that at greater than third versions. (New versions are potentially a vehicle for spamming our announcement feed, so we try to keep an eye on superfluous revisions.)
The 355 new papers we accepted in the previous 30 days reflect an annual pace of about 4,300 papers, which would be 37% above the 2025 pace.
My Stata code to retrieve metadata for the last 30 days of SocArXiv papers is available here.
In light of record submission rates and a large volume of AI-generated slop papers, SocArXiv recently implemented a policy requiring ORCID accounts linked in the OSF profile of submitting authors, and narrowing our focus to social science subjects (see this announcement). Today we are taking two more steps:
1. We are pausing new submissions about AI topics for 90 days. That is, papers about AI models, testing AI models, proposing AI models, theories about the future of AI and so on. We will make exceptions for papers that are already accepted for publication (or already published) in peer-reviewed scholarly journals. And we will make exceptions for empirical social science research about AI in society – for example, a study on how AI use affects workers in an organization – on a case-by-case basis. The purpose of this pause is to make it faster and easier for moderators to reject these papers, and encourage these authors to find other ways of distributing their work.
If your empirical social science research paper on an AI topic is rejected and you would like to appeal, please email us a link to the paper at socarxiv@gmail.com with a short note of explanation. We apologize for requiring this step.
2. We are developing a policy for AI-related work. We need a better, formal policy on AI-generated and LLM-assisted content. We have formed a committee of volunteers from our social science and library science networks to gather existing policies from other services and publications, and decide what policy is right for us. This includes the values we want to support, the work we are able to do, and the technical needs and requirements we have in doing our moderation and hosting. We hope this policy will be ready to implement when the 90-day pause on AI-related papers ends.
If you have expertise or suggestions for us in this work, we would appreciate hearing from you.
SocArXiv is experiencing record high submission rates. In addition, now that we have paper versioning – which is great – our moderators have to approve every paper revision. As a result, our volunteer workload is increasing.
In addition we are receiving many non-research, spam, and AI-generated submissions. We do not have a technological way of identifying these, and it is time-consuming to read and assess them according to our moderation rules.
We also don’t have moderation workflow tools that allow us to, for example, sort incoming papers by subject, to get them to specific expert moderators. So all our moderators look at all papers as they come in. That encourages us to think about narrowing the range of subjects we accept.
The two rule changes below are intended to help manage the increased moderator burden. More policy changes may follow if the volume keeps increasing.
1. ORCID requirement
We require the submitting author to have a publicly accessible ORCID linked from the OSF profile page, with a name that matches that on the paper and the OSF account.
In the case of non-bibliographic submittors (e.g., a research assistant submitting for a supervisor), the first author must have an ORCID. We can make exceptions for institutional submitters upon request, such as journals that upload their papers for authors.
At present we are not requiring additional verification or specific trust markers on the ORCID (such as email or employer verification), just the existence of an account that lists the author’s name. It’s not a foolproof identity verification, obviously, but it adds a step for scammers, and also helps identify pseudonymous authors, which we do not permit. We may take advantage of ORCID’s trust markers program in the future and require additional elements on the ORCID record.
We are happy to host papers by independent scholars, but a disproportionate share of non-research, spam, and AI-generated submissions come from independent scholars, many of whom do not have ORCIDs. For those scholars with institutional affiliations, we urge you to get an ORCID. This is a good practice that we should all endorse.
2. Focus on social sciences
At its founding, SocArXiv did not want to maintain disciplinary boundaries. It was our intention to be the big paper server for all of social sciences, and we couldn’t draw an easy line between social sciences and some humanities subjects, especially history, philosophy, religious studies, and some area studies, which are humanities in the taxonomy we use, but have significant overlap with social sciences. It was more logical just to accept them all.
As the volume has increased, this has become less practical. In addition, a lot of junk and AI submissions are in the areas of religion, philosophy, and various language studies. We also don’t have moderators working in arts and humanities, and our moderators trained in social sciences are not expert at reviewing these papers. Finally, there is an excellent, open humanities archive: Knowledge Commons (KC Works), which is freely available for humanities scholars. With approval from that service, we will now direct authors to their site for papers we are rejecting in arts and humanities subjects.
We continue to accept papers in education and law, which are also generally adjacent to social science.
For a limited time we will accept revisions of papers we already host in arts and humanities, but urge those authors to include links to Knowledge Commons or somewhere else that can host their work in the future.
We will assess papers that include arts/humanities as well as social science subject identifiers, and if we determine they are principally in art/humanities, reject them.
We will continue to host all work we have already accepted.
The Kohli Foundation for Sociology has announced that SocArXiv is the winner of its 2025 Infrastructure Prize for Sociology. This honor especially recognizes the leadership of SocArXiv founder Professor Philip N. Cohen of the Department of Sociology.
SocArXiv (pronounced “sosh-archive”) is an innovative open archive of the social sciences, providing a free, nonprofit, open access platform for social scientists to upload working papers, preprints, and published papers, with the option to link research materials such as data and code.
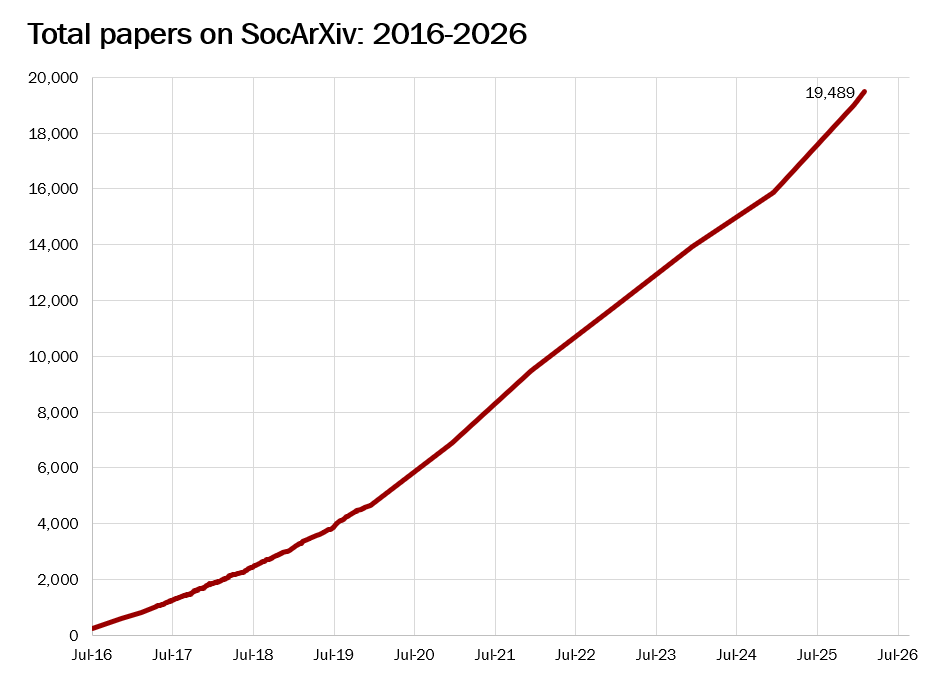
SocArXiv now hosts 17,000 papers across all disciplines in social sciences, arts, humanities, education, and law, in many languages. It is institutionally housed by the UMD libraries and operates on the Open Science Platform of the Center for Open Science.
“With the support of the UMD Libraries, and our platform at the Center for Open Science, we do it all at no charge for authors or readers, on a surprisingly small annual budget and a dedicated team of volunteers working a couple of hours a week,” Cohen said.
“The UMD Libraries and SocArXiv are partners in supporting open and equitable access to research for the public good. We are proud to serve as SocArXiv’s institutional home and congratulate SocArXiv on this well-deserved recognition,” said Interim Dean of the University Libraries Daniel Mack.
This Kohli Infrastructure Prize honors scholars, projects, and organizations that have made exceptional contributions to the development of substantial infrastructures that advance sociological knowledge, and comes with an award of 10,000 euros, more than $11,000.
SocArXiv is one of the efforts in which Cohen is involved that focuses on reforming the system of scholarly communication. He often speaks on the topic of how scholars can productively engage with public audiences, to improve work and deepen its impact. He explores related topics in his new book, “Citizen Scholar: Public Engagement for Social Scientists” (Columbia University Press, 2025).
“SocArXiv has been a labor of love for me since 2016, helping thousands of researchers to get their work done, but the efforts of myself and our volunteers often go unnoticed. So it’s wonderful to have this recognition,” Cohen said. “SocArXiv is a nonprofit, academy-owned and directed, collaborative project of volunteers from sociology and other social sciences, and members of the library community. This recognition honors that collective effort to pave a new way forward in scholarly communication. There is a lot we can do ourselves—faster, better, and cheaper than we can under the big academic publishers—and we’re proving it every day.”
“These papers are often available before journal publication, allowing them to disseminate further, and faster,” Cohen said.
The platform’s many-hands-on-deck approach has facilitated knowledge sharing even during difficult times. For example, a draft paper on learning losses amid COVID-related school closures was uploaded to SocArXiv and downloaded tens of thousands of times, and was therefore serving as a resource and point of reference to countless scholars and researchers before it was ultimately published in PNAS. This kind of open exchange of information and ideas has helped researchers to be more nimble and more productive.
Looking ahead, Cohen said he and his collaborators are working to make the repository a place for hosting peer review projects as well, so that people who want to conduct peer review in a transparent setting—with evolving versions, reviews and replies—can integrate their work onto SocArXiv.
As collaboration and knowledge sharing are priorities of the College of Behavioral and Social Sciences, Dean Susan Rivera said this recognition of Cohen and the networks that SocArXiv has forged is especially meaningful.
“Our college community congratulates Professor Cohen and his collaborators. It is fitting that their impactful work promoting open science is being honored in this significant way,” Rivera said. “This important platform is a point of pride for BSOS.”
Cohen has been invited to represent SocArXiv at the foundation’s awards ceremony in November at the European University Institute in Fiesole, Florence, Italy. Cohen has also been invited to be a guest on a Kohli Foundation podcast.
“A key priority of SocArXiv is to open up social science, to reach more people more effectively, to improve research, and build the future of scholarly communication,” Cohen said. “We hope that the visibility this award brings will draw more scholars and users to the platform.”
News! SocArXiv host OSF now supports better versioning of papers, making it easier to cite, share, and update papers – and new versions are moderated. This will also support new, more transparent publishing models. For details and guidance, see this guide from our hosts at OSF: https://help.osf.io/article/673-update-a-new-version-of-a-preprint. Ask us if you need help!
The SocArXiv steering committee joins the preprint services arXiv and ioRxiv/medRxiv in their recent statements in support of the U.S. Office of Science and Technology Policy (OSTP) memo that directs the federal government to make outputs from government-funded research publicly accessible without charge or embargo. We endorse these statements, and reproduce them below.
The recent Office of Science and Technology Policy “Nelson Memorandum” on “Ensuring Free, Immediate, and Equitable Access to Federally Funded Research”1 is a welcome affirmation of the public right to access government funded research results, including publication of articles describing the research, and the data behind the research. The policy is likely to increase access to new and ongoing research, enable equitable access to the outcome of publicly funded research efforts, and enable and accelerate more research. Improved immediate access to research results may provide significant general social and economic benefits to the public.
Funding Agencies can expedite public access to research results through the distribution of electronic preprints of results in open repositories, in particular existing preprint distribution servers such as arXiv,2 bioRxiv,3 and medRxiv.4 Distribution of preprints of research results enables rapid and free accessibility of the findings worldwide, circumventing publication delays of months, or, in some cases, years. Rapid circulation of research results expedites scientific discourse, shortens the cycle of discovery and accelerates the pace of discovery.5
Distribution of research findings by preprints, combined with curation of the archive of submissions, provides universal access for both authors and readers in perpetuity. Authors can provide updated versions of the research, including “as accepted,” with the repositories openly tracking the progress of the revision of results through the scientific process. Public access to the corpus of machine readable research manuscripts provides innovative channels for discovery and additional knowledge generation, including links to the data behind the research, open software tools, and supplemental information provided by authors.
Preprint repositories support a growing and innovative ecosystem for discovery and evaluation of research results, including tools for improved accessibility and research summaries. Experiments in open review and crowdsourced commenting can be layered over preprint repositories, providing constructive feedback and alternative models to the increasingly archaic process of anonymous peer review.
Distribution of research results by preprints provides a well tested path for immediate, free, and equitable access to research results. Preprint archives can support and sustain an open and innovative ecosystem of tools for research discovery and verification, providing a long term and sustainable approach for open access to publicly funded research.
The preprint servers bioRxiv and medRxiv welcome the recent Office of Science and Technology Policy (OSTP) memo advising US government agencies to make publications and data from research funded by US taxpayers publicly accessible immediately, without embargo or cost. This new policy will stimulate research, increase equitability, and generate health, environmental and social benefits not only in the US but all around the world.
Agencies can enable free public access to research results simply by mandating that reports of federally funded research are made available as “preprints” on servers such as arXiv, bioRxiv, medRxiv, and chemRxiv, before being submitted for journal publication. This will ensure that the findings are freely accessible to anyone anywhere in the world. An important additional benefit is the immediate availability of the information, avoiding the long delays associated with evaluation by traditional scientific journals (typically around one year). Scientific inquiry then progresses faster, as has been particularly evident for COVID research during the pandemic.
Prior access mandates in the US and elsewhere have focused on articles published by academic journals. This complicated the issue by making it a question of how to adapt journal revenue streams and led to the emergence of new models based on article-processing charges (APCs). But APCs simply move the access barrier to authors: they are a significant financial obstacle for researchers in fields and communities that lack the funding to pay them. A preprint mandate would achieve universal access for both authors and readers upstream, ensuring the focus remains on providing access to research findings, rather than on how they are selected and filtered.
Mandating public access to preprints rather than articles in academic journals would also future-proof agencies’ access policies. The distinction between peer-reviewed and non-peer-reviewed material is blurring as new approaches make peer review an ongoing process rather than a judgment made at a single point in time. Peer review can be conducted independently of journals through initiatives like Review Commons. And traditional journal-based peer review is changing: for example, eLife, supported by several large funders, peer reviews submitted papers but no longer distinguishes accepted from rejected articles. The author’s “accepted” manuscript that is the focus of so-called Green Open Access policies may therefore no longer exist. Because of such ongoing change, mandating the free availability of preprints would be a straightforward and strategically astute policy for US funding agencies.
A preprint mandate would underscore the fundamental, often overlooked, point that it is the results of research to which the public should have access. The evaluation of that research by journals is part of an ongoing process of assessment that can take place after the results have been made openly available. Preprint mandates from the funders of research would also widen the possibilities for evolution within the system and avoid channeling it towards expensive APC-based publishing models. Furthermore, since articles on preprint servers can be accompanied by supplementary data deposits on the servers themselves or linked to data deposited elsewhere, preprint mandates would also provide mechanisms to accomplish the other important OSTP goal: availability of research data.
Richard Sever and John Inglis Co-Founders, bioRxiv and medRxiv Cold Spring Harbor Laboratory, New York, NY11724
Harlan Krumholz and Joseph Ross Co-founders, medRxiv Yale University, New Haven, CT06520
Even with the very simple technique of tagging papers, we can facilitate enhanced collaboration among scholars and public sharing of scholarship — and when those two goals are met together, it is to the benefit of both.
When you submit a paper to SocArXiv, you have the opportunity to add tags. (You can also do this after your paper is posted, by going back to Edit Paper.) Those tags are then easily searchable for you or others. For example if you go to socarxiv.org and type:
tags:("covid-19")
into the search bar, you get this page, with the clunky URL:
which lists the 600+ papers that have used the COVID-19 tag. (Unfortunately, the tags aren’t clickable links on SocArXiv paper pages, but you can search for them.)
Scholarship communities
This simple tagging tool allows for relatively spontaneous grouping of scholarship, as when someone says, “We need to organize the recent work on police violence,” and people start uploading and tagging their work. But it just as well facilitates more organized efforts. Just as such groupings use Twitter hashtags to pull people together, we can do the same thing with scholarship using SocArXiv. Groups that might benefit from this tool include:
Working groups on a research topic
Panels for an upcoming conference
Departments or groups within departments
Sections of a professional association
Scholar-activist groups
Any such group can simply share the instructions above and notify participants of the associated tag. For example, if you are organizing a workshop or conference, you can make the meeting more productive by encouraging people to post their papers in advance, and use a common tag, such as “CairoMeeting2023,” or even “CairoMeeting2023-session-12”. Then you can share the URL for the search on that tag as in your preparatory materials or program.
We’re happy to help get you off the ground with your collaborative work. Feel free to contact us.
We posted our decision to withdraw the paper, “Ivermectin and the odds of hospitalization due to COVID-19″, here. Since then there have been new developments. I will update this page if needed. -Philip Cohen
As of February 5.
Statements
The lead author on the paper, José Merino, tweeted a link to a letter to me over the names of six of the original seven authors. The letter called the decision to withdraw their paper “unethical, colonialist, and authoritarian,” and demanded my resignation. You can read the statement here.
Sobre la decisión de @familyunequal de eliminar del sitio que dirige el análisis sobre Ivermectina y Covid en la CDMX. Le enviamos la siguiente respuesta. https://t.co/RCsi7h7efs
The Secretaría de Salud de la Ciudad de México posted a statement (in Spanish; English translation here), arguing that the use of ivermectin to treat COVID-19 was “supported by the scientific evidence available worldwide in 2020,” before the availability of vaccines, due its documented effectiveness, low cost, and lack of harmful effects. Distributing the medicine was not an experiment, they wrote. In addition, about SocArXiv, they wrote: “This study was kept on the SocArxiv portal for almost a year, it always had code and data available for replication, and its conclusions are very similar to other works (Ascencio-Montiel et al. 2022).” (Note, that study, which used the same data from the Mexico City COVID-19 health kit distribution, acknowledged that the kids “included, besides an information brochure and a pulse oxymeter, medications such as azithromycin, ivermecin, acetaminophen and aspirin” — and the study made no claims about the effects of ivermectin itself, and the data doesn’t indicate who took which medicines.)